Machine learning-based weather prediction (MLWP) is increasingly useful for operational weather forecasting. This AI paradigm, which is different than ‘traditional’ numerical weather prediction, builds on top of developments in computer vision and language modelling from the past decade. Development of these models is accelerating in recent years.
In this article, which is part of a series on AI-based weather forecasting, we will develop an intuitive understanding of these developments and how they translate to weather forecasting with AI. It helps the reader navigate all forthcoming articles, which will zoom in to the individual models and developments that are on the horizon.
We start by providing a high-level context about the rise of neural networks in the fields of computer vision and language modelling. Perhaps, it seems strange, but these developments have caused the nascence of AI-based weather forecasting! Subsequently, we focus on the base approaches used by the AI weather models. Then, we will further introduce the articles that are forthcoming.
The rise of neural networks in computer vision and language modelling
People have always been fascinated by making machines intelligent. Being established during the 1950s – the decade in which computing really took off – the field of Artificial Intelligence meant an increase in research into intelligent systems, whatever that meant at the time. Machine intelligence came in many forms – two of which are computer vision (where machines can interpret images and act upon their interpretation) and language modelling (where machines would be able to understand written text and generate responses).
Through a series of breakthroughs and plateaus, partially thanks to an exponential growth of computing power, the field established a set of techniques with which to handle images and text. In the early 2010s, however, these techniques were still fairly limited in terms of effectiveness – to detect specific objects (such as an orange in an image), highly specialized algorithms were written that contained many rules (such as “color must be orange” and “the detected shape must be round”). Modelling text was even more limited.
The first breakthrough that would eventually lead to today’s AI developments came in 2012. A group of researchers proposed to use a specific type of neural network for solving a computer vision problem, which required assigning the correct label (such as “orange”) to an image (Krizhevsky et al., 2012). A neural network is a computerized attempt to mimic the structure of the human brain, establishing a system which can learn from examples. In the case of assigning correct labels (a process called classification), the colors of the individual image pixels are passed to the network, which produces the prediction for what’s in it as its output.
The specific type of neural network, a convolutional neural network, is analogous to a magnifying glass. If you use one yourself, inspecting a picture, you can observe a high level of detail, informing you about what is in the image. You could then use that information to make an educated guess. The same thing happens within this type of neural network – by training it, a variety of ‘magnifying glasses’ learn to detect specific details relevant to the labels, allowing the network to distinguish oranges from, say, apples, bananas and other fruits.
The paper by Krizhevsky et al. (2012) triggered a wave of AI developments. Especially in the field of computer vision, between 2012 and 2017, new developments followed each other rapidly. The field of language modelling, however, plateaued – as these developments were difficult to apply there. This changed in 2017, when a group of Google researchers proposed the Transformer architecture, radically changing the way in which language models worked (Vaswani et al., 2017). By entering the whole text into the network (instead of word by word), letting the neural network focus on attention (i.e. the interrelationships between words), a way more powerful approach emerged. When combining this with a vast increase in learning power (through increasing the vastness of training text and model size), eventually breakthrough AI text tools like (Chat)GPT emerged (Radford et al., 2018; Radford et al., 2019; Brown et al., 2020; OpenAI, 2022).
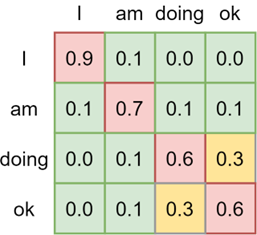
Within a Transformer model, using large quantities of text, the relationships between words are learned. By doing this hierarchically, relationships between individual words, larger spans of words and entire texts can be learned. This builds up textual understanding, which can then be used for e.g. generating new text. Image from Versloot (2020).
The developments of the past decade are highly relevant for this article, as they have trickled down into the field of weather forecasting in the years that followed. Realizing the power of Transformer architectures in language modelling, computer vision researchers started applying them to vision problems too – leading to Vision Transformers – and eventually leading to AI-based weather models like Pangu-Weather. What’s more, given the observation that increases in dataset size yield vastly better models, the meteorological sciences realized that they had a dataset of their own – namely, the ECMWF Reanalysis 5 (ERA5) dataset, covering decades of observations assimilated into the ECMWF weather model framework. Why not try and use that for AI-based weather forecasting?
AI applied to the atmosphere: different approaches
Modelling atmospheric state changes is relatively simple from a high level: use the current state of the atmosphere to model the next one. However, there are many ways in which this can be done. In this section, we’re introducing four of these methods. Specifically, we’ll focus on Vision Transformers, neural operators, graph neural networks and diffusion models. Quite some jargon, but don’t worry – our explanation is as intuitive as possible!
Vision Transformers: atmospheric states as images
Let’s briefly revisit the Transformer architecture discussed above. Recall that during training and usage, texts are entered at once – and that a hierarchy of layers learns word-level, word span-level and text-level relationships. This powerful approach has also proved to be useful for computer vision, given the introduction of Vision Transformers (Dosovitskiy et al., 2020). Whereas textual Transformers consider the input to be individual words, Vision Transformers cut an image into small patches (i.e., pieces) which are then fed through the Transformer model.
The authors of Pangu-Weather were inspired by this approach (Bi et al., 2022). Using the Vision Transformer as a base, they developed a new type of Vision Transformer called a 3D Earth-Specific Transformer, which considers that the Earth is a sphere. Still, it cuts the atmospheric state – represented as images – into patches (i.e., pieces) before feeding them to the model, which is an encoder-decoder model. In the encoder, using attention, small-scale weather phenomena are first learned followed by larger scale to large-scale weather phenomena. The decoder then uses these learned relationships to generate the output of the model, which is the next state of the atmosphere.
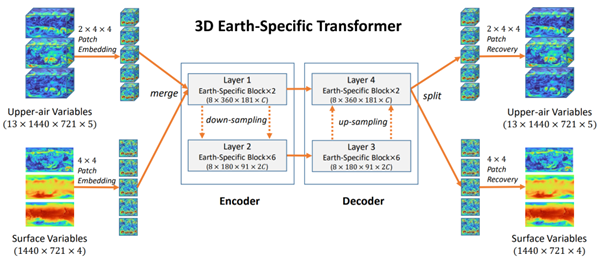
The internals of the Pangu-Weather model (Bi et al., 2022). Upper-air variables and surface variables are images, which are then cut into patches; see the left part of the image). Using an encoder-decoder architecture with Transformer layers, the model learns to produce the next state of the atmosphere as pieces, which are then recombined into images.
Neural operators: the FourCastNet series
Looking at the attention matrix for textual Transformers visualized above, it’s easy to see that increasing the maximum allowed text length (i.e., the context size) means scaling the matrix and thus required compute quadratically. This problem is also present within Vision Transformers and limits the number of variables that can be used. Specifically, longer-range sequences (such as long texts or weather somewhere on Earth influencing weather a lot farther away) are difficult to mix and thus model. This decreases the performance of models like Pangu-Weather.
In 2022, however, Guibas et al. proposed the Adaptive Fourier Neural Operator – or AFNO. This approach, building on top of the Fourier Neural Operator (FNO), first transforms the inputs into a different domain (the frequency domain). This helps reduce the required amount of computation and hence allows for training models faster. What’s more, equations used in NWP models can be learned in a data-driven way through AFNOs, which is a step closer to how physics-based models work compared to Pangu-Weather.
NVIDIA’s research team used these developments to develop the FourCastNet model, which stands for Fourier ForeCasting Neural NetWork. It uses a Vision Transformer like Pangu-Weather, with the AFNO applied within the encoder-decoder layers. This was quickly extended by work on FourCastNet version 2, which introduces a new type of FNO (the Spherical FNO) which solves problems with AFNO because the Earth is a sphere (Bonev et al., 2023).
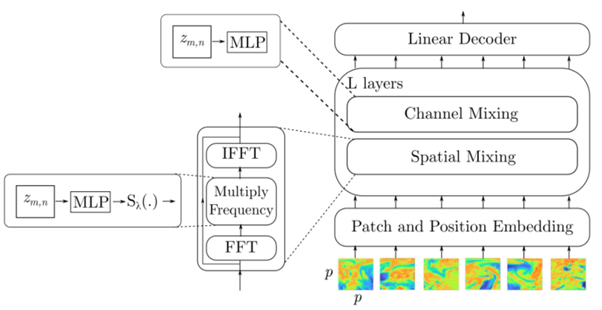
FourCastNet’s layers first transform all patches into the Fourier domain before learning relationships between the different patches. After learning, they are converted back into the regular domain after which relationships between the variables are considered. Image from Pathak et al. (2022).
Graph neural networks: hey, weather is coming your way
NWP models work by means of a grid, that is collections of points representing the domain of interest with some distance in between (i.e., what is known as the model resolution). Using physics-based equations, the current state of the atmosphere as expressed through these points is then computed forward in time, producing a weather forecast. This structure looks a bit like a graph structure, which is "a structure amounting to a set of objects in which some pairs of the objects are in some sense [related, and] represented by (...) points (...) [and connected via] edges" (Wikipedia, 2024). A simple, unstructured graph with 6 points is visualized below.
A graph. Figure from Wikipedia (2024).
The GraphCast model, developed by Google DeepMind, benefits from this analogy (Lam et al., 2022). Using a type of machine learning method called graph neural networks, the model first learns to encode specific weather as a graph, having many resolutions at once, to account for small-scale and large-scale weather phenomena. Then, its processor learns to pass messages between points – as if one point tells the other that weather is coming their way. Finally, the decoder then converts this representation back to a forecast for the next time step.
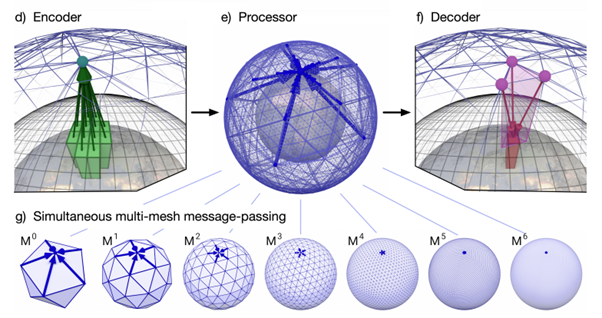
GraphCast first encodes the current state of the weather to graph points representing multiple meshes with varying resolutions (Lam et al., 2022).
Diffusion models: constructing atmospheric states from noise
Before wrapping up, let’s look at one final approach to modelling the weather using AI – which is through a process called diffusion. Many of today’s generative AI tools, among which OpenAI’s DALL·E 3 model and Stable Diffusion’s model, use this approach. It works by iteratively destroying many images by adding noise in a stepwise fashion. If you do this often enough, there is nothing left but noise. Subsequently, you can train a model to do the opposite – reconstructing the original image given a random noise sample (to be precise, from a Gaussian distribution). It sounds bizarre, but it works – insert noise, get an image!

The learned diffusion decoder: give it noise, get an image. Image from Ho et al. (2020).
However, it doesn’t stop at simple image generation. In fact, as you may have observed if you have seen AI-generated images before, these images are sharp. Recent works have benefited from this observation by sharpening AI-generated weather forecasts, which tend to become blurry after some time into the future (Zhong et al., 2023). For example, the FuXi-Extreme model uses a conditional diffusion model for making surface-level variables of the AI-based FuXi model sharper. By using the output of the FuXi model as a condition, the generated weather situation can be used to drive the generation process. This improves the outputs of AI-based weather forecasts because extremes are captured better due to increased sharpness.
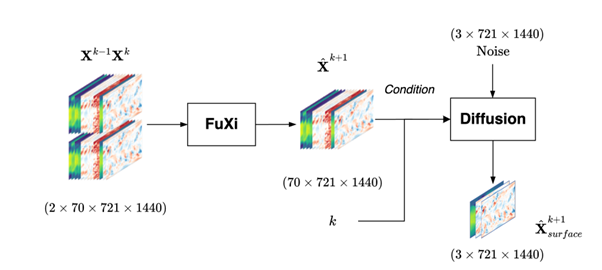
The FuXi-Extreme model. Figure from Zhong et al. (2023).
Next up in our AI series
Now that we understand the generics of MLWP models, it’s time to introduce the outline of our series about AI-based weather modelling. The next articles will cover the individual models in more detail and more! For example, in the next article, we’ll focus on the initial wave of AI-based weather models, including models such as Pangu-Weather, FourCastNet and GraphCast and their performance.
This is followed by the newer generation of weather models, before we focus on key development areas – which are using observations directly and better capturing extremes. Subsequently, we look at evaluating AI-based weather models with WeatherBench. Finally, we focus on reducing uncertainty through AI-based ensemble modelling, making models more regional and what limitations need to be tackled in the months and years to come.
The initial wave of AI-based weather models
Introducing Pangu-Weather, GraphCast and FourCastNet, the first series of 0.25 x 0.25 degree weather models that surpassed NWP models in some cases.
Next generation AI-based weather models
Introducing ECMWF’s AIFS model, FuXi and the FengWu series, which are newer generation AI-based weather models that attempt to overcome certain limitations.
Evaluating AI-based weather models with WeatherBench
Introduces the WeatherBench benchmarking suite, which can be used to consistently evaluate AI-based weather models. What’s more, it allows for comparison between models.
Going beyond analyses - using observations more directly
Today’s AI-based weather models are reliant on NWP analyses – but new approaches are trying to work around this limitation.
Better capturing extremes with sharper forecasts
One of the downsides of AI-based weather models is increased blurring further ahead in time as well as difficulty capturing extreme weather events. Similarly, new approaches have emerged attempting to mitigate this problem.
AI-based ensemble weather modelling
Weather is inherently uncertain. The speed with which AI-based weather forecasts can be generated enables scenario forecasting with significantly more scenarios to further reduce uncertainty.
AI-based limited-area modelling
Today’s weather models are global. Can we also extend AI-based weather forecasting to regional models with higher resolution? First attempts for this have emerged.
Future directions for AI-based weather modelling
To conclude the series, we look into future directions for research into AI-based weather modelling, such as physical consistency, NWP-AI hybrids and further overcoming limitations.
References
Bi, K., Xie, L., Zhang, H., Chen, X., Gu, X., & Tian, Q. (2022). Pangu-weather: A 3d high-resolution model for fast and accurate global weather forecast. arXiv preprint arXiv:2211.02556.Bonev, B., Kurth, T., Hundt, C., Pathak, J., Baust, M., Kashinath, K., & Anandkumar, A. (2023, July). Spherical fourier neural operators: Learning stable dynamics on the sphere. In International conference on machine learning (pp. 2806-2823). PMLR.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Guibas, J., Mardani, M., Li, Z., Tao, A., Anandkumar, A., & Catanzaro, B. (2021). Adaptive fourier neural operators: Efficient token mixers for transformers. arXiv preprint arXiv:2111.13587.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
Lam, R., Sanchez-Gonzalez, A., Willson, M., Wirnsberger, P., Fortunato, M., Alet, F., ... & Battaglia, P. (2022). GraphCast: Learning skillful medium-range global weather forecasting. arXiv preprint arXiv:2212.12794.
OpenAI. (2022). Introducing ChatGPT. https://openai.com/blog/chatgpt
Pathak, J., Subramanian, S., Harrington, P., Raja, S., Chattopadhyay, A., Mardani, M., ... & Anandkumar, A. (2022). Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators. arXiv preprint arXiv:2202.11214.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
Versloot, C. (2020, December 28). Introduction to transformers in machine learning. MachineCurve.com | Machine Learning Tutorials, Machine Learning Explained. https://machinecurve.com/index.php/2020/12/28/introduction-to-transformers-in-machine-learning
Wikipedia. (2024, April 14). Graph (discrete mathematics). Wikipedia, the free encyclopedia. Retrieved April 25, 2024, from https://en.wikipedia.org/wiki/Graph_(discrete_mathematics)
Zhong, X., Chen, L., Liu, J., Lin, C., Qi, Y., & Li, H. (2023). FuXi-Extreme: Improving extreme rainfall and wind forecasts with diffusion model. arXiv preprint arXiv:2310.19822.
Interested in our upcoming articles about AI and marine weather modeling? Subscribe to our marine newsletter and don't miss a thing.
